Blog

Importando dados com o Oracle SQL*Loader
O Oracle SQL*Loader é um utilitário presente tanto na instalação do Oracle Server quanto na instalação do Oracle client e sua função é basicamente ler arquivos textos e inserir os dados no banco de dados.
-
Permite carregar dados via rede, ou seja, o arquivo de dados pode estar em um sistema diferente do banco de dados (userid=username/password@instance);
-
Permite carregar dados de vários arquivos de dados durante a mesma sessão de carga;
-
Permite Carregar dados em várias tabelas durante a mesma sessão de carga;
-
Permite especificar o conjunto de caracteres (CHARACTERSET) dos dados;
-
Permite carregar dados de forma seletiva (pode carregar registos com base nos valores dos registos) - "when" categoria='Bebida';
-
Permite a manipulação dos dados antes de carregá-los, usando funções SQL;
-
Permite gerar valores sequencias para uma determinada coluna, entre outras.
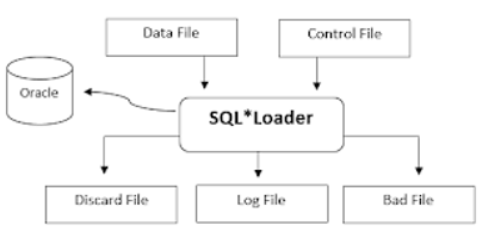
O SQL*Loader, assim como diversos outros utilitários Oracle, está abaixo do $ORACLE_HOME/bin sendo identificado pelo nome sqlldr.
Fazendo uma simples chamada, sem nenhum parâmetro, podemos ver diversas opções/comandos de utilização.
[oracle@db2 ~]$ sqlldr SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 15:02:07 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Usage: SQLLDR keyword=value [,keyword=value,...] Valid Keywords: userid -- ORACLE username/password control -- control file name log -- log file name bad -- bad file name data -- data file name discard -- discard file name discardmax -- number of discards to allow (Default all) skip -- number of logical records to skip (Default 0) load -- number of logical records to load (Default all) errors -- number of errors to allow (Default 50) rows -- number of rows in conventional path bind array or between direct path data saves (Default: Conventional path 64, Direct path all) bindsize -- size of conventional path bind array in bytes (Default 256000) silent -- suppress messages during run (header,feedback,errors,discards,partitions) direct -- use direct path (Default FALSE) parfile -- parameter file: name of file that contains parameter specifications parallel -- do parallel load (Default FALSE) file -- file to allocate extents from skip_unusable_indexes -- disallow/allow unusable indexes or index partitions (Default FALSE) skip_index_maintenance -- do not maintain indexes, mark affected indexes as unusable (Default FALSE) commit_discontinued -- commit loaded rows when load is discontinued (Default FALSE) readsize -- size of read buffer (Default 1048576) external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE columnarrayrows -- number of rows for direct path column array (Default 5000) streamsize -- size of direct path stream buffer in bytes (Default 256000) multithreading -- use multithreading in direct path resumable -- enable or disable resumable for current session (Default FALSE) resumable_name -- text string to help identify resumable statement resumable_timeout -- wait time (in seconds) for RESUMABLE (Default 7200) date_cache -- size (in entries) of date conversion cache (Default 1000) no_index_errors -- abort load on any index errors (Default FALSE) partition_memory -- direct path partition memory limit to start spilling (kb) (Default 0) table -- Table for express mode load date_format -- Date format for express mode load timestamp_format -- Timestamp format for express mode load terminated_by -- terminated by character for express mode load enclosed_by -- enclosed by character for express mode load optionally_enclosed_by -- optionally enclosed by character for express mode load characterset -- characterset for express mode load degree_of_parallelism -- degree of parallelism for express mode load and external table load trim -- trim type for express mode load and external table load csv -- csv format data files for express mode load nullif -- table level nullif clause for express mode load field_names -- field names setting for first record of data files for express mode load dnfs_enable -- option for enabling or disabling Direct NFS (dNFS) for input data files (Default FALSE) dnfs_readbuffers -- the number of Direct NFS (dNFS) read buffers (Default 4) PLEASE NOTE: Command-line parameters may be specified either by position or by keywords. An example of the former case is 'sqlldr scott/tiger foo'; an example of the latter is 'sqlldr control=foo userid=scott/tiger'. One may specify parameters by position before but not after parameters specified by keywords. For example, 'sqlldr scott/tiger control=foo logfile=log' is allowed, but 'sqlldr scott/tiger control=foo log' is not, even though the position of the parameter 'log' is correct.
Para Exemplificar alguns casos de uso do SQL*Loader foi criado a seguinte tabela:
SQL> create table produtos ( codigo number, nome varchar2(100), categoria varchar2(50), data_inclusao date ); Table created.
Arquivo de dados que será utilizado em alguns exemplos:
[oracle@db2 ~]$ cat dados1.txt 1,Shampoo,Higiene,16-MAR-17 2,Creme Dental,Higiene,16-MAR-17 3,Detergente,Limpeza,16-MAR-17 4,Alvejante,Limpeza,16-MAR-17 5,Amaciante,Limpeza,16-MAR-17 6,Refrigerante,Bebida,16-MAR-17 7,Agua,Bebida,16-MAR-17 8,Cerveja,Bebida,16-MAR-17 9,Suco,Bebida,16-MAR-17 10,Whisky,Bebida,16-MAR-17
1. Carregando os dados ("normal")
[oracle@db2 ~]$ cat exemplo1.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo1.bad' discardfile '/home/oracle/exemplo1.dsc' into table produtos fields terminated by "," ( codigo, nome, categoria, data_inclusao )
ERRORS: Independente da quantidade de erros que ocorram, o processo de carga deve continuar, por isso o número alto. Caso nenhum erro seja permitido ajuste o valor para 0. O valor padrão deste parâmetro é 50;
ROWS: Frequência de commits, ou seja, no exemplo a cada 5 linhas inseridas irá ocorrer um commit;
CHARACTERSET: Character set utilizado;
INFILE: Nome do arquivo texto que contém os dados que serão importados baseado nas configurações do control file;
BADFILE: Arquivo texto que será criado dos os registros rejeitados;
DISCARDFILE: Arquivo texto que será criado com os registros descartados mediante as condições de carga;
FIELDS TERMINATED BY: É o delimitador das colunas, ou seja, sempre que o caractere definido for encontrado significa que uma nova coluna se inicia.
Executando o SQL*Loader para carregar os registros contidos no arquivo dados1.txt baseado nas configurações do arquivo de controle (control file).
oracle@db2 ~]$ sqlldr anderson/anderson@pdb1 control=exemplo1.ctl SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 15:04:08 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Path used: Conventional Commit point reached - logical record count 5 Commit point reached - logical record count 10 Table PRODUTOS: 10 Rows successfully loaded. Check the log file: exemplo1.log for more information about the load.
Finalizada a execução, a saída do comando irá informar o nome do log gerado (Check the log file: exemplo1.log), nele existirá detalhes adicionais da carga.
[oracle@db2 ~]$ cat exemplo1.log SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 15:04:08 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Control File: exemplo1.ctl Character Set WE8ISO8859P1 specified for all input. Data File: /home/oracle/dados1.txt Bad File: /home/oracle/exemplo1.bad Discard File: /home/oracle/exemplo1.dsc (Allow all discards) Number to load: ALL Number to skip: 0 Errors allowed: 9999999 Bind array: 5 rows, maximum of 256000 bytes Continuation: none specified Path used: Conventional Table PRODUTOS, loaded from every logical record. Insert option in effect for this table: INSERT Column Name Position Len Term Encl Datatype ------------------------------ ---------- ----- ---- ---- --------------------- CODIGO FIRST * , CHARACTER NOME NEXT * , CHARACTER CATEGORIA NEXT * , CHARACTER DATA_INCLUSAO NEXT * , CHARACTER Table PRODUTOS: 10 Rows successfully loaded. 0 Rows not loaded due to data errors. 0 Rows not loaded because all WHEN clauses were failed. 0 Rows not loaded because all fields were null. Space allocated for bind array: 5160 bytes(5 rows) Read buffer bytes: 1048576 Total logical records skipped: 0 Total logical records read: 10 Total logical records rejected: 0 Total logical records discarded: 0 Run began on Thu Mar 16 15:04:08 2017 Run ended on Thu Mar 16 15:04:09 2017 Elapsed time was: 00:00:00.40 CPU time was: 00:00:00.01
Registros na tabela PRODUTOS do banco de dados:
SQL> set lines 200 SQL> col nome for a30 SQL> col categoria for a20 SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo Higiene 16-MAR-17 2 Creme Dental Higiene 16-MAR-17 3 Detergente Limpeza 16-MAR-17 4 Alvejante Limpeza 16-MAR-17 5 Amaciante Limpeza 16-MAR-17 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 10 Whisky Bebida 16-MAR-17 10 rows selected.
2. Inserindo dados adicionais
Após a inserção dos registros do arquivo dados1.txt se tornou necessário inserir alguns registros adicionais, desta forma, o SQL*Loader foi novamente executado informando um segundo arquivo de dados chamado dados2.txt, contudo ocorreu ocorre um erro informando que a tabela PROTUDOS precisa estar vazia.
[oracle@db2 ~]$ sqlldr anderson/anderson@pdb1 control=exemplo2.ctl SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 15:20:37 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Path used: Conventional SQL*Loader-601: For INSERT option, table must be empty. Error on table PRODUTOS
Como o arquivo dados2.txt contém apenas registros adicionais, será utilizado o comando APPEND que instrui o SQL*Loader a "acrescentar" os registros do arquivo dados2 na tabela PRODUTOS.
[oracle@db2 ~]$ cat dados2.txt 11,Trigo,Cereal,16-MAR-17 12,Arroz,Cereal,16-MAR-17
Arquivo de controle contendo o comando APPEND:
[oracle@db2 ~]$ cat exemplo2.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados2.txt' badfile '/home/oracle/exemplo2.bad' discardfile '/home/oracle/exemplo2.dsc' append into table produtos fields terminated by "," ( codigo, nome, categoria, data_inclusao )
Execução do SQL*Loader para carregar os dados adicionais:
[oracle@db2 ~]$ sqlldr anderson/anderson@pdb1 control=exemplo2.ctl SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 15:28:12 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Path used: Conventional Commit point reached - logical record count 2 Table PRODUTOS: 2 Rows successfully loaded. Check the log file: exemplo2.log for more information about the load.
Verificando se os registros foram acrescentados a tabela com sucesso:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo Higiene 16-MAR-17 2 Creme Dental Higiene 16-MAR-17 3 Detergente Limpeza 16-MAR-17 4 Alvejante Limpeza 16-MAR-17 5 Amaciante Limpeza 16-MAR-17 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 10 Whisky Bebida 16-MAR-17 11 Trigo Cereal 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 12 Arroz Cereal 16-MAR-17 12 rows selected.
Caso os novos registros tenham sido adicionados no mesmo arquivo de dados anterior (dados1.txt), utilize o parâmetro TRUNCATE em vez de APPEND, desta forma, a tabela será primeiramente truncada e posteriormente os dados inseridos.
[oracle@db2 ~]$ cat exemplo3.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo3.bad' discardfile '/home/oracle/exemplo3.dsc' truncate into table produtos fields terminated by "," ( codigo, nome, categoria, data_inclusao )
Execução do SQL*Loader com o novo arquivo de controle (control file):
[oracle@db2 ~]$ sqlldr anderson/anderson@pdb1 control=exemplo3.ctl SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 15:37:06 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Path used: Conventional Commit point reached - logical record count 5 Commit point reached - logical record count 10 Commit point reached - logical record count 12 Table PRODUTOS: 12 Rows successfully loaded. Check the log file: exemplo3.log
3. Diferentes delimitadores
Em alguns cenários os delimitadores dos registros poderão ser diferentes, como no arquivo de dados abaixo:
[oracle@db2 ~]$ cat dados3.txt 1,Shampoo|Higiene^16-MAR-17 2,Creme Dental|Higiene^16-MAR-17 3,Detergente|Limpeza^16-MAR-17 4,Alvejante|Limpeza^16-MAR-17 5,Amaciante|Limpeza^16-MAR-17 6,Refrigerante|Bebida^16-MAR-17 7,Agua|Bebida^16-MAR-17 8,Cerveja|Bebida^16-MAR-17 9,Suco|Bebida^16-MAR-17 10,Whisky|Bebida^16-MAR-17 11,Trigo|Cereal^16-MAR-17 12,Arroz|Cereal^16-MAR-17
Para carregar estes dados, além do já configurado terminated by "," será adicionado após cada coluna no arquivo de controle um novo terminated by especificando o caractere necessário para quebrar cada coluna.
[oracle@db2 ~]$ cat exemplo4.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados3.txt' badfile '/home/oracle/exemplo4.bad' discardfile '/home/oracle/exemplo4.dsc' truncate into table produtos fields terminated by "," ( codigo, nome terminated by "|", categoria terminated by "^", data_inclusao )
Execução:
[oracle@db2 ~]$ sqlldr anderson/anderson@pdb1 control=exemplo4.ctl
Verificando os registros:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo Higiene 16-MAR-17 2 Creme Dental Higiene 16-MAR-17 3 Detergente Limpeza 16-MAR-17 4 Alvejante Limpeza 16-MAR-17 5 Amaciante Limpeza 16-MAR-17 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 10 Whisky Bebida 16-MAR-17 11 Trigo Cereal 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 12 Arroz Cereal 16-MAR-17 12 rows selected.
4. Formatando datatype DATE e definindo "tamanho fixo" para os dados
Da mesma forma que um arquivo de dados pode ter diferentes delimitadores, também é possível que ele não tenha qualquer delimitador. Utilizando o comando "position(start:end)" é possível delimitar onde começa e onde termina cada coluna/registro.
Na coluna DATA_INCLUSAO, datatype DATE, também é permitido aplicar mascaras, transformando-a conforme necessidade.
Arquivo de dados:
[oracle@db2 ~]$ cat dados4.txt 1Shampoo1Higiene16/03/2017 16:18:00 2Shampoo2Higiene16/03/2017 16:18:00 3Shampoo3Higiene16/03/2017 16:18:00 4Shampoo4Higiene16/03/2017 16:18:00
Arquivo de controle contendo a máscara para a data_inclusao e com as posições de início:fim de cada coluna/registro:
[oracle@db2 ~]$ cat exemplo5.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados4.txt' badfile '/home/oracle/exemplo5.bad' discardfile '/home/oracle/exemplo5.dsc' truncate into table produtos fields terminated by "," ( codigo position(1:1), nome position(2:9), categoria position(10:16), data_inclusao position(17:35) "to_date(trim(:data_inclusao),'DD/MM/YYYY HH24:MI:SS')" )
Registros inseridos:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo1 Higiene 16-MAR-17 2 Shampoo2 Higiene 16-MAR-17 3 Shampoo3 Higiene 16-MAR-17 4 Shampoo4 Higiene 16-MAR-17
5. Alterando os dados durante a carga
Nem sempre os dados de entrada representam o formato ou nome que é necessário que eles tenham no banco de dados. Para tanto podemos usar funções SQL para "transformar" estes dados durante o processo de carga.
No exemplo será utilizado o arquivo de dados dados1.txt, onde cada código será incrementado em +10, o nome convertido para UPPERCASE (Maiúsculo) e a categoria além do UPPERCASE será substituída por DESCONHECIDA quando a categoria de entrada (arquivo de dados) for Limpeza.
[oracle@db2 ~]$ cat exemplo6.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo6.bad' discardfile '/home/oracle/exemplo6.dsc' truncate into table produtos fields terminated by "," ( codigo ":codigo+10", nome "upper(:nome)", categoria "upper(decode(:categoria,'Limpeza','Desconhecida', :categoria))", data_inclusao )
Verificando se os registros foram alterados durante a carga de dados conforme especificado:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 11 SHAMPOO HIGIENE 16-MAR-17 12 CREME DENTAL HIGIENE 16-MAR-17 13 DETERGENTE DESCONHECIDA 16-MAR-17 14 ALVEJANTE DESCONHECIDA 16-MAR-17 15 AMACIANTE DESCONHECIDA 16-MAR-17 16 REFRIGERANTE BEBIDA 16-MAR-17 17 AGUA BEBIDA 16-MAR-17 18 CERVEJA BEBIDA 16-MAR-17 19 SUCO BEBIDA 16-MAR-17 20 WHISKY BEBIDA 16-MAR-17 21 TRIGO CEREAL 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 22 ARROZ CEREAL 16-MAR-17 12 rows selected.
6. Carregando dados de forma seletiva
Se nem todos os dados precisam ser carregados, basta inserir a clausula WHEN logo após o "into table" onde apenas os registros que satisfazerem a condição serão carregados para a tabela no banco de dados.
[oracle@db2 ~]$ cat exemplo7.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo7.bad' discardfile '/home/oracle/exemplo7.dsc' truncate into table produtos when categoria = 'Bebida' fields terminated by "," ( codigo, nome, categoria, data_inclusao )
Dados que foram inseridos na tabela PRODUTOS:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 10 Whisky Bebida 16-MAR-17
Como existem dados descartados em função da condição WHEN, o arquivo discardfile foi criado contendo os registros que foram descartados no processo de carga por não atenderem a condição imposta.
[oracle@db2 ~]$ cat exemplo7.dsc 1,Shampoo,Higiene,16-MAR-17 2,Creme Dental,Higiene,16-MAR-17 3,Detergente,Limpeza,16-MAR-17 4,Alvejante,Limpeza,16-MAR-17 5,Amaciante,Limpeza,16-MAR-17 11,Trigo,Cereal,16-MAR-17 12,Arroz,Cereal,16-MAR-17
7. Utilizando valores sequenciais
Nos exemplos até aqui utilizados, sempre existiu no arquivo de dados o código do produto, mas e se não existe? Pois bem, lembra da flexibilidade do SQL*Loader supracitada?
SEQUENCE(MAX): Especificado após o nome da coluna no arquivo de controle (control file) faz com que o SQL*Loader gere de forma sequencial os valores para a determinada coluna.
Arquivo de dados criado sem os códigos:
[oracle@db2 ~]$ cat dados5.txt Shampoo,Higiene,16-MAR-17 Creme Dental,Higiene,16-MAR-17 Detergente,Limpeza,16-MAR-17 Alvejante,Limpeza,16-MAR-17 Amaciante,Limpeza,16-MAR-17 Refrigerante,Bebida,16-MAR-17 Agua,Bebida,16-MAR-17 Cerveja,Bebida,16-MAR-17 Suco,Bebida,16-MAR-17 Whisky,Bebida,16-MAR-17 Trigo,Cereal,16-MAR-17 Arroz,Cereal,16-MAR-17
Arquivo de controle com o sequence(max) na coluna código:
[oracle@db2 ~]$ cat exemplo8.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados5.txt' badfile '/home/oracle/exemplo8.bad' discardfile '/home/oracle/exemplo8.dsc' truncate into table produtos fields terminated by "," ( codigo sequence(max), nome, categoria, data_inclusao )
Após a execução da carga, foram inseridos os seguintes registros na tabela PRODUTOS:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo Higiene 16-MAR-17 2 Creme Dental Higiene 16-MAR-17 3 Detergente Limpeza 16-MAR-17 4 Alvejante Limpeza 16-MAR-17 5 Amaciante Limpeza 16-MAR-17 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 10 Whisky Bebida 16-MAR-17 11 Trigo Cereal 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 12 Arroz Cereal 16-MAR-17 12 rows selected.
Caso seja necessário carregar mais dados, não tem problema. Altere o arquivo de controle substituindo o comando TRUNCATE por APPEND. O sequence(max) irá continuar a sequência sem problemas.
[oracle@db2 ~]$ cat dados6.txt Trigo,Cereal,16-MAR-17 Arroz,Cereal,16-MAR-17 [oracle@db2 ~]$ cat exemplo9.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados6.txt' badfile '/home/oracle/exemplo9.bad' discardfile '/home/oracle/exemplo9.dsc' append into table produtos fields terminated by "," ( codigo sequence(max), nome, categoria, data_inclusao )
Registros na tabela PRODUTOS após a carga de dados adicional:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 13 Trigo Cereal 16-MAR-17 14 Arroz Cereal 16-MAR-17 1 Shampoo Higiene 16-MAR-17 2 Creme Dental Higiene 16-MAR-17 3 Detergente Limpeza 16-MAR-17 4 Alvejante Limpeza 16-MAR-17 5 Amaciante Limpeza 16-MAR-17 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 10 Whisky Bebida 16-MAR-17 11 Trigo Cereal 16-MAR-17 12 Arroz Cereal 16-MAR-17 14 rows selected.
Além da opção nativa do SQL*Loader ainda é possível utilizar sequences criadas na própria base de dados, contudo a antiga coluna de código ainda deve existir no arquivo de dados, caso contrário será gerado erro.
Será utilizado o arquivo de dados - dados1.txt para a simulação.
SQL> create sequence seq_tst1 start with 5 increment by 5; Sequence created.
Arquivo de controle especificando a sequência criada no banco de dados:
[oracle@db2 ~]$ cat exemplo10.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo10.bad' discardfile '/home/oracle/exemplo10.dsc' truncate into table produtos fields terminated by "," ( codigo "SEQ_TST1.nextval", nome, categoria, data_inclusao )
Realizada a carga, seguem os dados carregados:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 5 Shampoo Higiene 16-MAR-17 10 Creme Dental Higiene 16-MAR-17 15 Detergente Limpeza 16-MAR-17 20 Alvejante Limpeza 16-MAR-17 25 Amaciante Limpeza 16-MAR-17 30 Refrigerante Bebida 16-MAR-17 35 Agua Bebida 16-MAR-17 40 Cerveja Bebida 16-MAR-17 45 Suco Bebida 16-MAR-17 50 Whisky Bebida 16-MAR-17 55 Trigo Cereal 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 60 Arroz Cereal 16-MAR-17 12 rows selected.
Outra opção para trabalhar com uma sequence da base de dados é via trigger, ou seja, a coluna código deve ser removida do arquivo de controle da mesma forma que no arquivo de dados também não é mais necessário.
Será utilizado o arquivo de dados - dados5.txt para a simulação, onde não existem valores "codigo".
Trigger criada na base de dados:
SQL> create trigger trg_seq_tst1 before insert on produtos for each row begin select seq_tst1.nextval into :new.codigo from dual; end; / Trigger created.
Arquivo de controle onde foi removido a coluna "codigo":
[oracle@db2 ~]$ cat exemplo11.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados5.txt' badfile '/home/oracle/exemplo11.bad' discardfile '/home/oracle/exemplo11.dsc' truncate into table produtos fields terminated by "," ( nome, categoria, data_inclusao )
Registros após a nova carga dos dados utilizando o arquivo de controle exemplo11.ctl:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 65 Shampoo Higiene 16-MAR-17 70 Creme Dental Higiene 16-MAR-17 75 Detergente Limpeza 16-MAR-17 80 Alvejante Limpeza 16-MAR-17 85 Amaciante Limpeza 16-MAR-17 90 Refrigerante Bebida 16-MAR-17 95 Agua Bebida 16-MAR-17 100 Cerveja Bebida 16-MAR-17 105 Suco Bebida 16-MAR-17 110 Whisky Bebida 16-MAR-17 115 Trigo Cereal 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 120 Arroz Cereal 16-MAR-17 12 rows selected.
8. Carregando dados de múltiplos arquivos de dados
Para carregar dados de múltiplos arquivos, insira múltiplos infile dentro do arquivo de controle.
[oracle@db2 ~]$ cat exemplo12.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' infile '/home/oracle/dados2.txt' badfile '/home/oracle/exemplo12.bad' discardfile '/home/oracle/exemplo12.dsc' truncate into table produtos fields terminated by "," ( codigo, nome, categoria, data_inclusao )
Como no meu arquivo de dados dados1.txt atualmente existem registros duplicados com o dados2.txt, será criado uma primary key (PK) na tabela PRODUTOS sobre a coluna codigo de forma a não importar dados duplicados e gerar o arquivo badfile com os registros rejeitados.
SQL> alter table produtos add constraint pk_cod primary key(codigo); Table altered.
Execução da carga:
[oracle@db2 ~]$ sqlldr anderson/anderson@pdb1 control=exemplo12.ctl SQL*Loader: Release 12.1.0.2.0 - Production on Thu Mar 16 19:43:39 2017 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Path used: Conventional Commit point reached - logical record count 5 Commit point reached - logical record count 10 Commit point reached - logical record count 12 Commit point reached - logical record count 14 Table PRODUTOS: 12 Rows successfully loaded. Check the log file: exemplo12.log for more information about the load.
Arquivos rejeitados (badfile) – O nome do caminho/arquivo é o configurado no arquivo de controle, neste caso /home/oracle/exemplo12.bad:
[oracle@db2 ~]$ cat exemplo12.bad 11,Trigo,Cereal,16-MAR-17 12,Arroz,Cereal,16-MAR-17
Erro gerado no arquivo de log que justificam os registros rejeitados:
[oracle@db2 ~]$ cat exemplo12.log | grep ORA- ORA-00001: unique constraint (ANDERSON.PK_COD) violated ORA-00001: unique constraint (ANDERSON.PK_COD) violated
Registros que foram inseridos:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo Higiene 16-MAR-17 2 Creme Dental Higiene 16-MAR-17 3 Detergente Limpeza 16-MAR-17 4 Alvejante Limpeza 16-MAR-17 5 Amaciante Limpeza 16-MAR-17 6 Refrigerante Bebida 16-MAR-17 7 Agua Bebida 16-MAR-17 8 Cerveja Bebida 16-MAR-17 9 Suco Bebida 16-MAR-17 10 Whisky Bebida 16-MAR-17 11 Trigo Cereal 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 12 Arroz Cereal 16-MAR-17 12 rows selected.
9. Carregando dados em múltiplas tabelas
Assim como para carregar múltiplos arquivos basta inserir outros infile no arquivo de controle, para carregar os dados em múltiplas tabelas basta inserir outros into table.
Neste exemplo será criado uma nova tabela chamada CATEGORIA onde teremos o código da categoria e seu respectivo nome.
SQL> create table categoria ( codigo number, nome varchar2(100) ); Table created.
Na tabela PRODUTOS não existirá mais o nome da categoria, mas o código da categoria que fara referência a tabela CATEGORIA. Desta forma, o arquivo de controle foi ajustado para:
[oracle@db2 ~]$ cat exemplo13.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo13.bad' discardfile '/home/oracle/exemplo13.dsc' truncate into table produtos fields terminated by "," ( codigo, nome, categoria "decode(:categoria,'Higiene','1','Limpeza','2','Bebida','3','Cereal','4',:categoria)", data_inclusao ) into table categoria fields terminated by "," trailing nullcols ( codigo "decode(:nome,'Higiene','1','Limpeza','2','Bebida','3','Cereal','4',:nome)", x filler position(1), y filler, nome )
O decode na categoria foi inserido para transformar o "nome da categoria" em "códigos" para os mesmos grupos.
No arquivo de dados existem 4 colunas/registros para cada linha, diferentemente da tabela PRODUTOS a tabela CATEGORIA possui apenas 2 colunas e que não seguem a mesma sequência das colunas no arquivo de dados.
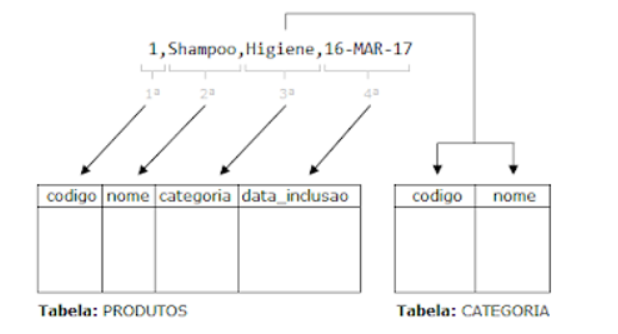
Para ler apenas a 3ª coluna de cada linha e popular corretamente a tabela CATEGORIA foi inserido o comando TRAILING NULLCOLS para que quando não houverem valores eles sejam nulos e foi criado colunas fictícias com o comando FILLER para simular as colunas do arquivo de dados.
Posterior a coluna código da CATEGORIA existe o FILLER x e y além da coluna nome. No arquivo de dados a coluna que contém os dados do nome da categoria é a 3ª e não a 4ª coluna, isto é necessário pois quando se trabalha com múltiplas tabelas e diferentes colunas de inserção o delimitador acaba se perdendo e para voltar ao início da linha foi atribuído junto ao comando FILLER da coluna x o comando position(1), por isso existem mais 3 colunas após a coluna categoria, justamente para simular as colunas fictícias desde o início de cada linha (null,null,CATEGORIA).
Executando a carga dos dados:
[oracle@db2 ~]$ cat exemplo13.ctl options (errors=9999999, rows=5) load data characterset WE8ISO8859P1 infile '/home/oracle/dados1.txt' badfile '/home/oracle/exemplo13.bad' discardfile '/home/oracle/exemplo13.dsc' truncate into table produtos fields terminated by "," ( codigo, nome, categoria "decode(:categoria,'Higiene','1','Limpeza','2','Bebida','3','Cereal','4',:categoria)", data_inclusao ) into table categoria fields terminated by "," trailing nullcols ( codigo "decode(:nome,'Higiene','1','Limpeza','2','Bebida','3','Cereal','4',:nome)", x filler position(1), y filler, nome )
Registros carregados na tabela PRODUTOS:
SQL> select * from produtos; CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 1 Shampoo 1 16-MAR-17 2 Creme Dental 1 16-MAR-17 3 Detergente 2 16-MAR-17 4 Alvejante 2 16-MAR-17 5 Amaciante 2 16-MAR-17 6 Refrigerante 3 16-MAR-17 7 Agua 3 16-MAR-17 8 Cerveja 3 16-MAR-17 9 Suco 3 16-MAR-17 10 Whisky 3 16-MAR-17 11 Trigo 4 16-MAR-17 CODIGO NOME CATEGORIA DATA_INCL ---------- ------------------------------ -------------------- --------- 12 Arroz 4 16-MAR-17 12 rows selected.
Pelo output (saída) da execução do SQL*Loader já é perceptível que ocorreu a inserção de 12 linhas também na tabela CATEGORIA, mas temos apenas 4 distintas categorias. Como não é possível trabalhar com distinct no SQL*Loader, basta agora remover os valores duplicados da tabela CATEGORIA.
SQL> delete from categoria A where rowid > (select min(rowid) from categoria B where a.codigo = b.codigo and a.nome = b.nome ); 8 rows deleted. SQL> commit; Commit complete. SQL> select * from categoria; CODIGO NOME ---------- ------------------------------ 1 Higiene 2 Limpeza 3 Bebida 4 Cereal
Além das opções e comandos citados que já tornam o SQL*Loader uma poderosa ferramenta, ainda existem diversas outras parametrizações e comandos que podem ser empregados na sua configuração deixando-o ainda mais rápido (direct, parallel, etc) e versátil (skip, begindata, dnfs_enable, etc).




